Google 搜尋引擎的演算法一直不斷再進化,不過很多人對搜尋引擎的理解,還停留在資料庫全文檢索(Full-Text index)的概念,其實從第一版的 Google Search Engine,用的就不是傳統資料庫系統內建的全文檢索功能,而是自行開發的資料庫及索引系統,要了解目前的搜尋引擎是著重在語意分析後的搜尋,才不至於停留在關鍵字比對的思維。
關鍵字比對與斷詞有甚麼關係呢!?
舉個案例說明,如果你到 Google Trends 去查詢字詞的搜尋趨勢,你就會發現一些異象,我們以 2019 年台灣的熱門搜尋排行來說明,排行第一名搜尋的搜尋關鍵字是「我們與惡的距離」,網址在 : https://trends.google.com.tw/trends/yis/2019/TW/
當你把你的滑鼠游標,移到 我們與惡的距離 時,瀏覽器下方會出現連結的網址,如下圖。
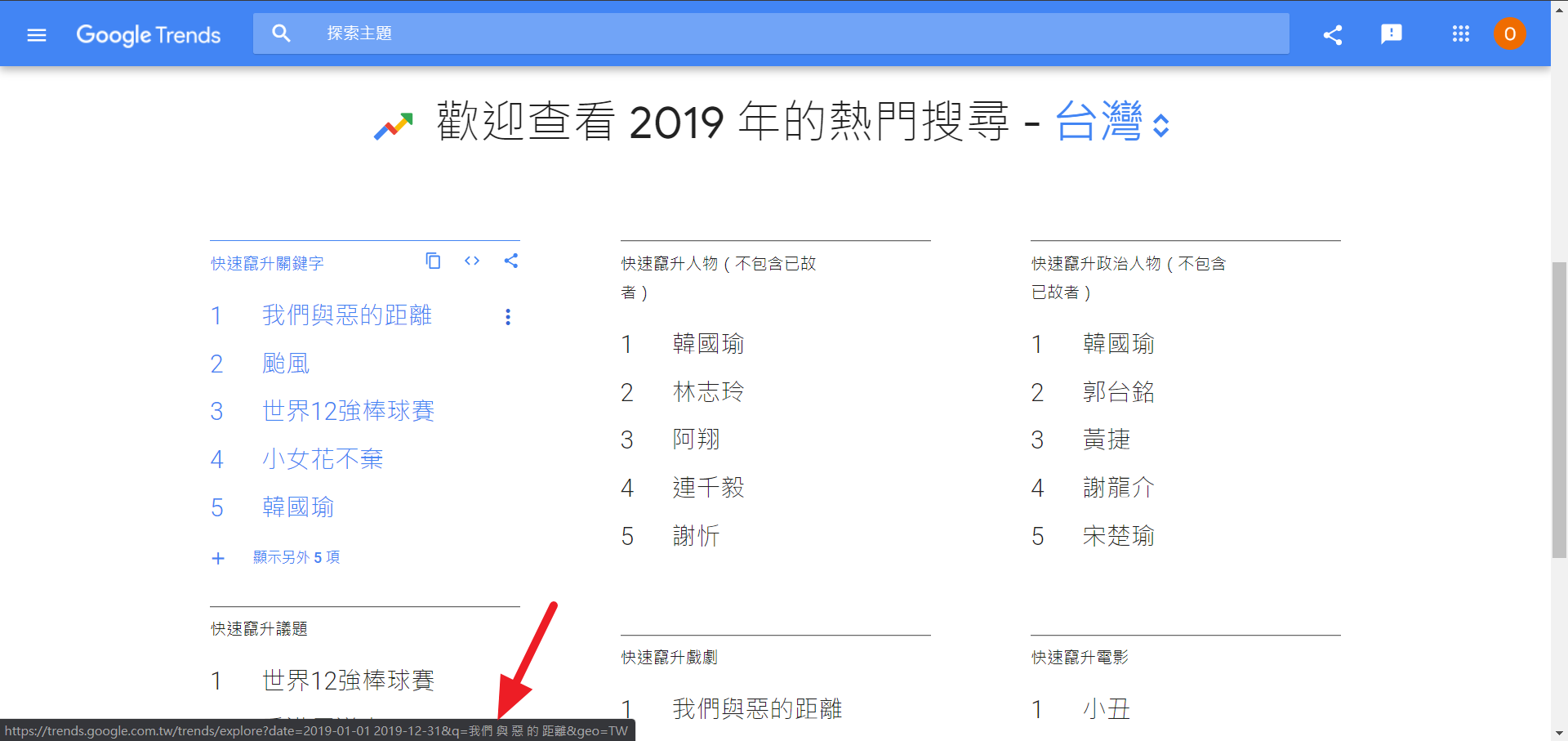
但請注意看,連結網址中的參數 q 所帶入的值,並不是
q=我們與惡的距離
而是
q=我們 與 惡 的 距離
原本的詞被許多空白字元斷開了。
點擊連結開啟「我們與惡的距離」搜尋熱度的趨勢變化,會發現網頁所帶入的搜尋字詞,仍是被空白字元斷開的,這時候我們再自行新增一組沒有空白字元斷開的「我們與惡的距離」比較字詞,出現的畫面如下:
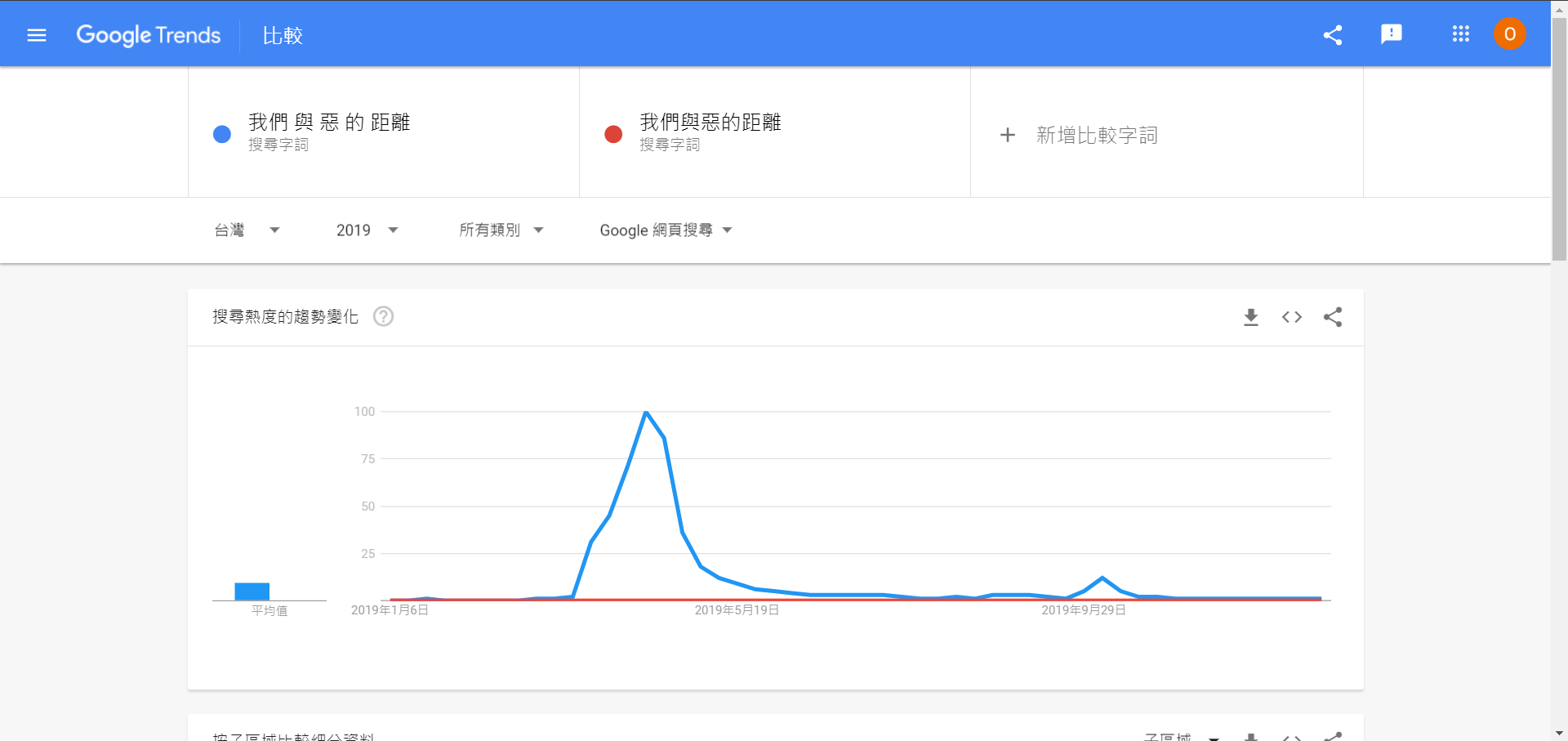
請注意紅色的線,幾乎是躺平的,這個圖表的意思是,2019 年根本沒什麼人在搜尋「我們與惡的距離」喔,大家都是搜尋「我們 與 惡 的 距離」啦。想要使用 Google Trends 去查詢字詞的搜尋趨勢,你可能要先了解一下中文全文檢索中的斷詞,再來研究 Google Trends 比較恰當。
=====================================================
MarTech 行銷科技洞察社團 - GA4、SEO、GTM、Search Console、Looker Studio、社群、內容、廣告
OpenCart 台灣技術支援 - OpenCart 網站代管、客製、維護
OpenCart 台灣電商社團 - 台灣 OpenCart 使用者交流
=====================================================
MarTech 行銷科技洞察社團 - GA4、SEO、GTM、Search Console、Looker Studio、社群、內容、廣告
OpenCart 台灣技術支援 - OpenCart 網站代管、客製、維護
OpenCart 台灣電商社團 - 台灣 OpenCart 使用者交流
=====================================================